在當今數據驅動的商業環境中,數據倉庫、數據指標、數據治理體系以及數據處理服務已成為企業實現數據價值的關鍵要素。本文將從核心概念出發,系統闡述數據倉庫的架構、數據指標的定義與管理、數據治理體系的建設方法論,并探討數據處理服務在現代數據平臺中的角色。
一、數據倉庫:企業數據的核心存儲與處理平臺
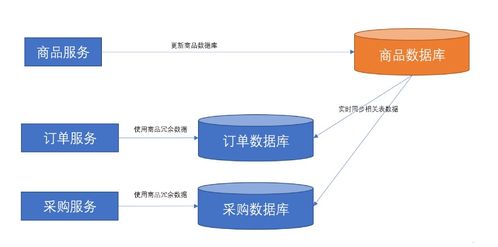
數據倉庫是一個集成的、面向主題的、穩定的數據存儲系統,用于支持企業決策分析。它通過ETL(提取、轉換、加載)過程,將來自多個源系統的數據整合到一個統一的模型中。數據倉庫通常采用分層架構,包括數據源層、數據存儲層(如ODS、數據倉庫、數據集市)和應用層。其核心優勢在于提供歷史數據分析和一致的數據視圖,幫助企業發現趨勢、優化運營。
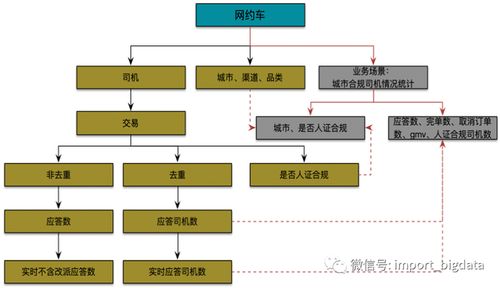
二、數據指標:量化業務表現的關鍵工具
數據指標是衡量業務績效的具體量化標準,如銷售額、用戶活躍度、轉化率等。有效的數據指標應具備可度量性、相關性、準確性和可操作性。企業需建立指標體系,將指標分為核心指標(如KPI)和衍生指標,并通過數據倉庫進行統一計算和存儲。管理數據指標時,需明確指標定義、計算邏輯、數據來源和更新頻率,避免歧義和錯誤使用。
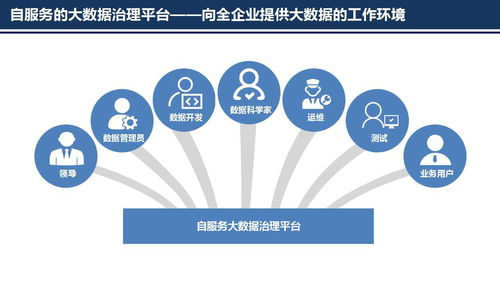
三、數據治理體系建設方法論:確保數據質量與合規性
數據治理是一套管理數據資產的政策、流程和標準,旨在提升數據質量、安全性和可用性。建設數據治理體系的方法論通常包括以下步驟:
- 戰略規劃:明確治理目標,獲得高層支持,制定路線圖。
- 組織架構:設立數據治理委員會和專職團隊,分配角色職責。
- 政策與標準:定義數據分類、質量標準、安全政策和元數據管理規范。
- 技術工具:引入數據目錄、數據質量工具和治理平臺,實現自動化監控。
- 流程實施:建立數據生命周期管理流程,包括數據采集、存儲、使用和銷毀。
- 持續改進:通過審計和反饋機制,優化治理效果。
該方法論強調文化與技術的結合,確保數據在合規框架下發揮最大價值。
四、數據處理服務:支撐數據流動與價值提取
數據處理服務包括數據集成、清洗、轉換和分析等環節,常通過云服務或自建平臺實現。現代數據處理服務采用分布式計算(如Hadoop、Spark)和流處理技術(如Kafka),支持實時和批量處理。服務化架構(如DataOps)提升了數據處理效率,允許企業快速響應業務需求。AI和機器學習的集成,使數據處理服務能夠自動化異常檢測和預測分析。
結語
數據倉庫、數據指標、數據治理體系和數據處理服務構成了企業數據管理的四大支柱。通過系統化建設,企業可構建可靠的數據基礎,驅動智能決策與創新。隨著技術演進,這些要素將更緊密融合,助力企業在數字時代保持競爭力。