作為中國領先的在線旅游服務平臺,攜程每天需要處理海量數據并支持高并發用戶訪問。本文結合攜程的實際案例,探討其大數據技術在高并發應用架構及推薦系統中的應用。
一、高并發應用架構設計
攜程的高并發架構基于微服務與分布式系統,通過水平擴展和負載均衡應對峰值訪問。核心組件包括:
- 服務拆分:將業務模塊拆分為獨立微服務,如訂單、支付、搜索等,提升系統可維護性和彈性。
- 緩存策略:采用多級緩存(如Redis集群)減少數據庫壓力,熱點數據預加載至內存。
- 異步處理:使用消息隊列(如Kafka)解耦服務,異步處理日志、通知等非實時任務。
- 數據庫優化:讀寫分離、分庫分表,結合NoSQL與關系型數據庫應對多樣化數據需求。
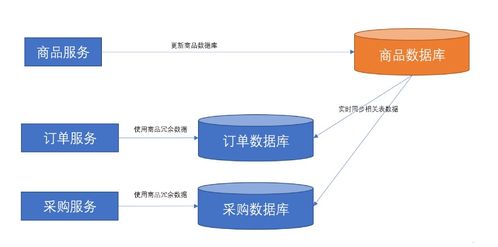
二、數據處理服務架構
攜程的數據處理服務覆蓋采集、存儲、計算與應用全流程:
- 數據采集:通過Agent、日志收集器實時捕獲用戶行為、交易數據。
- 數據存儲:構建數據湖,整合HDFS、HBase等存儲原始與加工數據。
- 計算引擎:利用Spark、Flink進行批流一體計算,實現實時指標分析與離線報表生成。
- 數據服務:通過API網關對外提供統一數據接口,支持業務系統低延遲查詢。
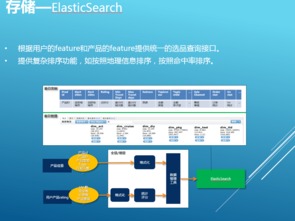
三、推薦系統案例實踐
攜程的推薦系統依托大數據處理能力,實現了個性化行程推薦:
- 數據基礎:整合用戶歷史瀏覽、搜索、訂單及地理位置數據,構建用戶畫像與物品畫像。
- 算法模型:采用混合推薦策略,包括協同過濾(基于用戶與物品關系)、深度學習(如Wide & Deep模型)處理非線性特征。
- 實時推薦:通過Flink處理實時用戶行為,動態調整推薦結果,提升轉化率。
- A/B測試:搭建實驗平臺,對比不同算法效果,持續優化推薦精準度。
四、總結與展望
攜程通過高并發架構保障系統穩定性,結合數據處理服務與推薦系統提升用戶體驗。隨著5G與AI技術發展,攜程將繼續探索實時數據分析、智能決策等方向,進一步強化大數據在旅游行業的應用價值。