隨著企業數字化轉型的深入,微服務架構因其高內聚、低耦合、獨立部署與彈性伸縮等優勢,已成為現代軟件系統設計的首選范式之一。在微服務架構下,數據設計與管理面臨新的挑戰與機遇。本文將快速解析微服務架構下的數據設計核心原則,并聚焦于數據處理服務的關鍵角色與實踐方法。
一、微服務數據設計的核心原則
微服務架構強調每個服務擁有自己的私有數據庫,即“數據庫按服務拆分”(Database per Service)。這一原則避免了傳統單體架構中數據庫成為單點故障和性能瓶頸的問題,但也帶來了數據一致性與事務管理的復雜性。因此,微服務數據設計的首要原則是:
- 領域驅動設計(DDD):通過界定限界上下文(Bounded Context),明確每個微服務的數據邊界與職責,確保數據模型與服務業務邏輯高度內聚。
- 數據自治:每個微服務獨立管理自身的數據存儲(如SQL、NoSQL),對外僅通過定義良好的API暴露數據操作,隱藏內部實現細節。
- 最終一致性:在分布式環境下,強一致性難以保證,通常采用最終一致性模型,通過事件驅動、消息隊列等方式異步同步數據。
二、數據處理服務的角色與定位
在微服務生態中,數據處理服務(Data Processing Service)扮演著至關重要的角色。它并非簡單的CRUD服務,而是專注于數據的轉換、聚合、清洗、分析與分發的專用服務。其主要職責包括:
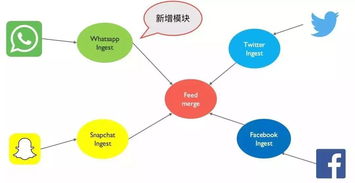
- 數據集成與同步:作為不同微服務間數據流動的橋梁,通過訂閱領域事件(Domain Events),將數據從源服務同步到目標服務或數據倉庫,確保數據在系統間的一致性視圖。
- 實時數據處理:利用流處理技術(如Apache Kafka, Apache Flink)對事件流進行實時計算,生成業務指標、觸發告警或更新衍生數據。
- 批量數據處理:處理歷史數據或大數據量的ETL(提取、轉換、加載)任務,支持離線分析與報表生成。
- 數據聚合與物化視圖:為滿足特定查詢需求,將分散在多個服務中的數據聚合起來,構建物化視圖(Materialized View),提升查詢性能并減少跨服務調用。
三、數據處理服務的關鍵設計模式
- Saga模式:用于管理跨多個微服務的分布式事務。數據處理服務可作為Saga的協調者或參與者,通過一系列補償性操作確保業務事務的最終一致性。
- CQRS(命令查詢職責分離):將數據的寫操作(命令)與讀操作(查詢)分離。數據處理服務常負責維護用于高效查詢的讀模型(Read Model),該模型通過訂閱寫模型(Write Model)的事件進行更新。
- 事件溯源(Event Sourcing):將系統狀態的變化存儲為一系列不可變的事件序列。數據處理服務可以消費這些事件流,重建當前狀態或構建各種投影(Projection),為不同場景提供定制化的數據視圖。
四、實踐建議與挑戰應對
- 技術選型:根據數據處理類型(實時/批量、吞吐量、延遲要求)選擇合適的中間件,如Kafka用于事件流,Redis用于緩存,Elasticsearch用于搜索,數據湖/倉用于分析。
- 彈性與容錯:設計數據處理服務時需考慮故障恢復、重試機制、死信隊列等,確保數據不丟失且處理可恢復。
- 數據契約與演化:服務間通過事件或API共享數據時,需定義清晰的數據契約(如使用Avro、Protobuf Schema),并制定向后兼容的演化策略,避免因數據格式變更導致服務中斷。
- 監控與可觀測性:對數據處理流水線的吞吐量、延遲、錯誤率進行全方位監控,并建立端到端的追蹤能力,以便快速定位數據不一致或處理滯后的根本原因。
五、
在微服務架構下,數據設計從“集中管控”轉向“分布式自治”,數據處理服務則成為維系數據生態健康運轉的核心組件。通過遵循領域驅動、事件驅動、最終一致性等原則,并合理運用Saga、CQRS、事件溯源等模式,可以構建出高彈性、可擴展且易于維護的數據處理體系。關鍵在于始終以業務價值為導向,在數據一致性、系統復雜度與開發運維成本之間找到最佳平衡點。