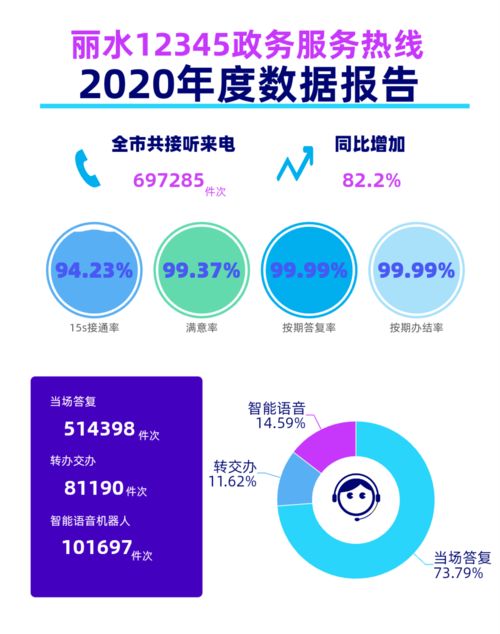
引言:從單體到微服務的演進
在傳統的單體應用架構中,數據處理往往作為一個模塊內嵌在龐大的代碼庫中。隨著業務規模擴大和系統復雜度增加,單體架構在部署、維護、擴展和技術棧選擇上逐漸暴露出瓶頸。微服務架構應運而生,它通過將單一應用拆分為一組小型、自治的服務來解決這些問題。每個服務圍繞特定業務能力構建,可以獨立開發、部署和擴展。本文將以一個核心的“數據處理服務”為例,深入探討如何使用Java技術棧構建和維護微服務。
微服務核心特征與數據處理服務的映射
- 單一職責:數據處理服務專注于數據的清洗、轉換、聚合、存儲與供給。它不處理用戶認證,也不處理訂單邏輯,其邊界清晰。
- 獨立部署與擴展:當數據量激增或計算任務繁重時,我們可以獨立地對數據處理服務進行水平擴展(如增加容器實例),而無需重新部署整個應用。
- 技術異構性:數據處理服務內部可以選擇最適合的技術棧。例如,核心業務邏輯用Java,高性能計算部分用Scala,甚至數據存儲可以選擇Elasticsearch或ClickHouse,而其他服務可能使用MySQL。
- 圍繞業務能力組織:數據處理本身就是一個明確的業務能力領域,是構建數據驅動型應用的基石。
構建Java數據處理微服務的核心技術棧
1. 服務開發框架
- Spring Boot:作為事實上的標準,它提供了快速構建獨立、生產級應用的能力。通過自動配置和起步依賴,可以輕松集成數據訪問、消息隊列等組件。
- Micronaut / Quarkus:作為新興的輕量級、云原生框架,它們在啟動速度、內存消耗方面具有優勢,尤其適合Serverless或容器化環境。
2. 服務間通信
數據處理服務需要與其他服務(如“訂單服務”、“用戶服務”)交互以獲取原始數據,并向“分析服務”、“報表服務”提供處理后的結果。
- RESTful API (Spring MVC / JAX-RS):最常用的同步通信方式,簡單直觀。
- RPC (gRPC / Apache Thrift):高性能、跨語言的通信框架,適用于對延遲敏感的內部服務調用。
- 異步消息 (Spring Cloud Stream / Apache Kafka / RabbitMQ):這是數據處理服務的核心模式。服務通過訂閱消息主題(如
raw-data-topic)接收數據,處理完成后將結果發布到另一個主題(如processed-data-topic),實現解耦和流量削峰。
3. 數據持久化與訪問
- 關系型數據庫:MySQL, PostgreSQL。適用于需要事務保證的結構化數據。
- NoSQL數據庫:
- MongoDB:處理半結構化或文檔型數據。
- Elasticsearch:用于全文檢索和日志數據分析。
- Redis:作為高速緩存,存儲熱點數據或中間計算結果。
- 數據訪問層:Spring Data JPA (用于RDBMS), Spring Data MongoDB, MyBatis等,極大地簡化了數據操作。
4. 服務治理與運維(Spring Cloud生態)
- 服務注冊與發現:Eureka, Consul, Nacos。數據處理服務啟動時向注冊中心注冊自己的地址。
- 配置中心:Spring Cloud Config, Nacos, Apollo。集中管理數據處理的規則、轉換邏輯的配置,實現動態更新。
- 負載均衡:Ribbon (客戶端負載均衡)。
- API網關:Spring Cloud Gateway。作為統一的入口,負責路由、鑒權、限流等,外部請求通過網關訪問數據處理服務的API。
- 熔斷與降級:Resilience4j (或Hystrix)。當數據處理服務依賴的“數據源服務”不可用時,快速失敗并提供降級響應(如返回緩存數據),防止級聯故障。
- 分布式追蹤:Sleuth + Zipkin。追蹤一個數據請求在多個微服務間的調用鏈路,便于性能分析和故障排查。
5. 部署與容器化
- Docker:將數據處理服務及其所有依賴打包成標準鏡像。
- Kubernetes (K8s):用于服務的編排、自動擴縮容、服務發現和負載均衡。通過定義Deployment、Service、ConfigMap等資源來管理數據處理服務。
一個典型的數據處理微服務設計示例
假設我們構建一個“用戶行為數據分析服務”。
- 職責:消費用戶點擊、瀏覽等原始事件流,進行實時清洗、會話歸因、指標聚合(如PV/UV),并將結果存儲和推送。
- 技術實現:
- 使用Spring Boot搭建應用骨架。
- 通過Spring Cloud Stream綁定Kafka,訂閱
user-event-topic。
- 核心業務邏輯:實現
StreamListener方法,對消息進行反序列化、校驗、轉換和聚合。
- 聚合結果寫入Elasticsearch供實時查詢,同時將關鍵指標寫入Redis緩存。
- 通過REST端點對外提供查詢接口。
- 服務信息注冊到Nacos,配置從Nacos Config讀取。
- 通過Resilience4j對寫入ES的操作進行熔斷保護。
- 使用Docker打包,通過K8s部署,并設置根據CPU使用率自動擴縮容。
挑戰與最佳實踐
- 數據一致性:在分布式環境下,放棄強一致性,擁抱最終一致性。使用事件驅動架構,通過發布“數據處理完成”事件來通知下游。
- 服務契約:使用OpenAPI (Swagger) 清晰地定義和文檔化REST API接口。對于消息,定義清晰的Avro或Protobuf Schema。
- 監控與可觀測性:除了鏈路追蹤,還需集成Metrics(如Micrometer + Prometheus + Grafana)監控服務的QPS、延遲、錯誤率及JVM狀態。集中化管理日志(ELK或Loki)。
- 測試:重視單元測試(業務邏輯)、集成測試(數據庫、消息)和契約測試(服務接口)。
- CI/CD:建立自動化流水線,實現從代碼提交到鏡像構建、部署到測試環境的全流程自動化。
##
以Java構建數據處理微服務,實質上是將復雜的數據處理系統拆分為一個高內聚、低耦合的獨立單元。通過合理運用Spring Boot/Cloud生態及各類中間件,我們可以構建出彈性、可擴展、易于維護的數據處理服務。關鍵在于明確服務邊界、設計松耦合的通信機制、并建立完善的運維監控體系。微服務不是銀彈,它引入了分布式系統的復雜性,但對于需要快速迭代、獨立擴展和處理海量數據的現代應用而言,它已成為主流的架構范式。數據處理服務作為其中的關鍵組件,其穩健性是整個系統數據驅動能力的核心保障。