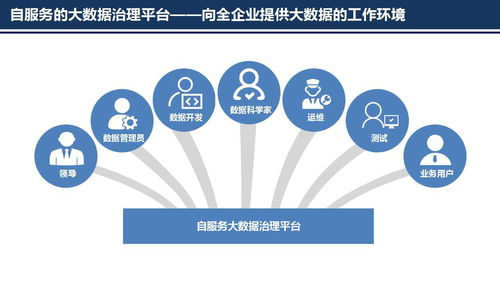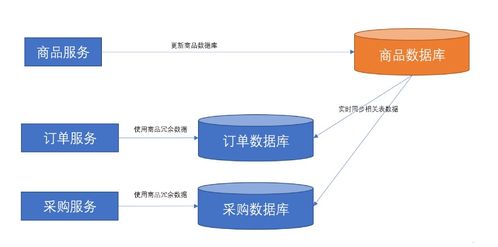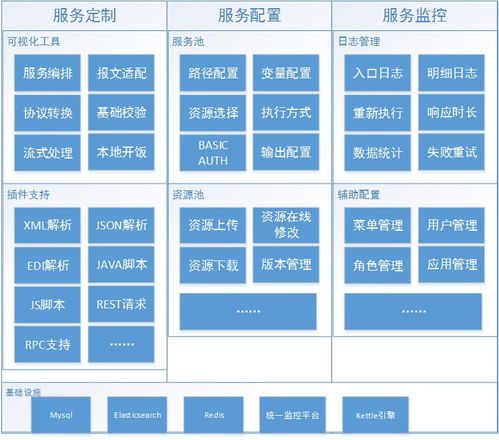
在數字化轉型浪潮中,ETL(抽取-轉換-加載)作為數據處理的核心環節,其功能復用已成為企業高效開發定制化服務的重要手段。本部分聚焦數據處理服務,探討如何基于ETL能力構建靈活、可擴展的數據服務解決方案。
一、理解ETL數據處理功能的核心價值
ETL工具通常具備數據清洗、格式轉換、規則校驗等標準化處理能力。以金融行業為例,原始交易數據通過ETL去重、補全時間戳、轉換幣種后,可直接轉化為合規報表。這些通用模塊(如數據脫敏、聚合計算)可通過API封裝為獨立服務,避免重復開發。
二、構建數據處理服務的三大策略
- 模塊化拆分:將ETL流程拆解為原子化處理單元(如地址標準化、異常檢測),通過微服務架構暴露為RESTful接口。例如電商平臺可將「用戶行為數據清洗」模塊復用至推薦系統和風控系統。
- 配置化驅動:開發可視化配置界面,允許業務人員通過拖拽方式組合數據處理流程。某物流企業通過配置字段映射規則,快速生成了不同國家的海關申報數據服務。
- 流水線編排:利用工作流引擎(如Apache Airflow)動態調度ETL任務鏈。當醫療科研需要整合多源患者數據時,可復用已有的「實驗室數據解析」服務,僅需新增基因序列轉換節點。
三、技術實現路徑
- 服務化封裝:使用Spring Boot等框架將ETL工具(如Talend、Kettle)的轉換邏輯包裝為gRPC或HTTP服務,支持異步處理和負載均衡。
- 元數據管理:建立數據處理能力目錄,記錄各服務的輸入輸出格式、性能指標和依賴關系,便于服務組合與優化。
- 資源隔離:通過Docker容器化部署,保障高優先級服務(如實時風控數據處理)的資源獨占性。
四、實踐案例與成效
某零售企業將商品ETL流水線中的「銷售數據歸一化」模塊服務化后:
- 供應鏈系統調用該服務計算補貨閾值,開發周期縮短60%
- 營銷系統復用服務生成區域熱力圖,數據準備成本降低75%
- 通過服務版本管理,實現了新舊稅率計算規則的無縫切換
五、演進方向
- 智能增強:集成機器學習模型,使數據處理服務具備自適應能力(如自動識別異常數據模式)
- 云原生升級:采用Serverless架構實現處理服務的按需擴縮容,進一步降低運維成本
通過將ETL的數據處理能力服務化,企業不僅能提升數據資產復用率,更可構建敏捷響應業務變化的定制化服務生態。關鍵在于平衡標準化與靈活性,讓數據流水線成為創新業務的助推器而非瓶頸。